-
Il carrello è vuoto!
Il carrello è vuoto!
La versione 3.3 di Moku introduce un nuovo strumento di Rete Neurale su Moku:Pro, che consente agli utenti di implementare reti neurali artificiali per un'analisi dei segnali rapida e flessibile, riduzione del rumore, condizionamento dei sensori, feedback a circuito chiuso e molto altro. Se non hai familiarità con le basi di una rete neurale o desideri scoprire come questa possa supportare i tuoi obiettivi di ricerca e sviluppo, continua a leggere per esplorare applicazioni reali e tutorial.
Innanzitutto, è importante notare che "rete neurale artificiale" (ANN) è il termine più corretto per questi sistemi, poiché sono basati su software e non su neuroni biologici. Tenendo presente questa precisazione, useremo il termine "rete neurale" per riferirci a una ANN. In questa introduzione, prenderemo in considerazione solo le reti neurali completamente connesse, escludendo configurazioni più complesse come le architetture convoluzionali, ricorrenti e transformer.
Le reti neurali sono composte da nodi, organizzati in strati. Il valore di un nodo dipende dal valore di uno o più nodi dello strato precedente. I nodi del primo strato (input) prendono il loro valore direttamente dall'input esterno, mentre i nodi nello strato finale (output) forniscono il risultato della rete. Gli strati tra input e output sono definiti strati nascosti.
In termini matematici, immagina lo strato di input come una matrice N ✕ 1, dove N è il numero di nodi nello strato di input e ciascun elemento nella matrice corrisponde al valore di attivazione, come mostrato in Figura 1.

Figura 1: Architettura della rete neurale, che mostra gli strati di input, nascosti e di output.
Successivamente ci sono gli strati nascosti. Il numero di strati nascosti e di nodi al loro interno dipende dalla complessità del modello e dalla potenza di calcolo disponibile. Le attivazioni negli strati nascosti vengono calcolate utilizzando una combinazione delle attivazioni dallo strato precedente, con ciascun nodo che applica pesi e bias differenti ai valori dello strato di input. Questo è mostrato in termini di algebra lineare nella Figura 2.

Figura 2: Le attivazioni negli strati nascosti vengono calcolate utilizzando una combinazione delle attivazioni dallo strato precedente.
Se lo strato di input è una matrice N ✕ 1 (n1, n2...), le attivazioni successive si ottengono moltiplicando questa per una matrice M ✕ N, dove M è il numero di nodi nello strato nascosto. Ogni elemento nella matrice è un peso rappresentato da wmn, il che significa che per ogni strato sono necessari MN parametri. Il risultato è una matrice M ✕ 1, che viene poi modificata con un valore di bias (b1, b2...). Dopo aver calcolato le nuove attivazioni, queste vengono passate attraverso una "funzione di attivazione". La funzione di attivazione può fornire un comportamento non lineare come il clipping e la normalizzazione, rendendo la rete molto più potente rispetto a una semplice serie di moltiplicazioni tra matrici.
Dopo essere passati attraverso diversi strati nascosti, i dati arrivano infine allo strato di output. Nei nodi di output, il valore dell'attivazione corrisponde a un parametro di interesse. Ad esempio, supponiamo che i dati di una serie temporale raccolti da un oscilloscopio siano inseriti nell'input e che l'obiettivo della rete sia classificare il segnale come onda sinusoidale, onda quadra, onda a dente di sega o segnale DC. Nello strato di output, ciascun nodo corrisponderebbe a una di queste opzioni, con l'attivazione di valore più alto che rappresenta la migliore ipotesi della rete sulla forma del segnale. Se un'attivazione è vicina a 1 e le altre sono vicine a 0, la fiducia della rete nella sua ipotesi è alta. Se le attivazioni sono simili tra loro, questo indica una bassa fiducia nella risposta.
Come funzionano le reti neurali?
Senza regolare i pesi e i bias degli strati nascosti, una rete neurale finisce per essere nient'altro che un complesso generatore di numeri casuali. Per migliorare l'accuratezza del modello, l'utente deve fornire dati di addestramento, in cui sono noti sia il set di dati di input che la risposta attesa. Il modello può quindi calcolare la propria risposta al set di addestramento, che può essere confrontata con il valore reale. La differenza calcolata, nota come funzione di costo, fornisce una valutazione quantitativa delle prestazioni del modello.
Dopo aver calcolato la funzione di costo per un determinato set di dati, i pesi e i bias degli strati nascosti possono essere regolati attraverso varie operazioni di calcolo, con l'obiettivo di minimizzare la funzione di costo. Questo è simile al concetto di discesa del gradiente nel calcolo vettoriale e può essere approfondito nella letteratura. Questo processo, chiamato backpropagation, consente alle informazioni ottenute tramite la funzione di costo di procedere a ritroso attraverso gli strati, portando il modello ad apprendere o ad adattarsi senza intervento umano.
I dati di addestramento vengono spesso eseguiti attraverso la rete neurale più volte. Ogni volta che questi dati vengono forniti al modello si parla di un’epoca. Tipicamente, una parte dei dati di addestramento viene riservata per la validazione. Durante la validazione, una rete addestrata viene utilizzata per dedurre output da questo set di dati riservato e le sue previsioni vengono confrontate con l'output corretto noto. Questo fornisce un quadro più accurato delle prestazioni del modello rispetto al solo valore della funzione di costo, poiché indica quanto bene il modello riesce a generalizzare i risultati per nuovi e inediti input.
Quali sono i diversi tipi di reti neurali?
Le reti neurali, pur operando su principi simili, possono assumere forme diverse a seconda dell'applicazione. Alcuni esempi comuni di reti neurali includono:
Come vengono utilizzate le reti neurali nell'elaborazione dei segnali?
Sebbene le reti neurali siano popolari per attività come il supporto a modelli di linguaggio di grandi dimensioni, la decodifica delle immagini e la traduzione, sono anche incredibilmente utili per l'elaborazione dei segnali. Alcuni esempi di come il machine learning possa migliorare un setup di misurazione includono:
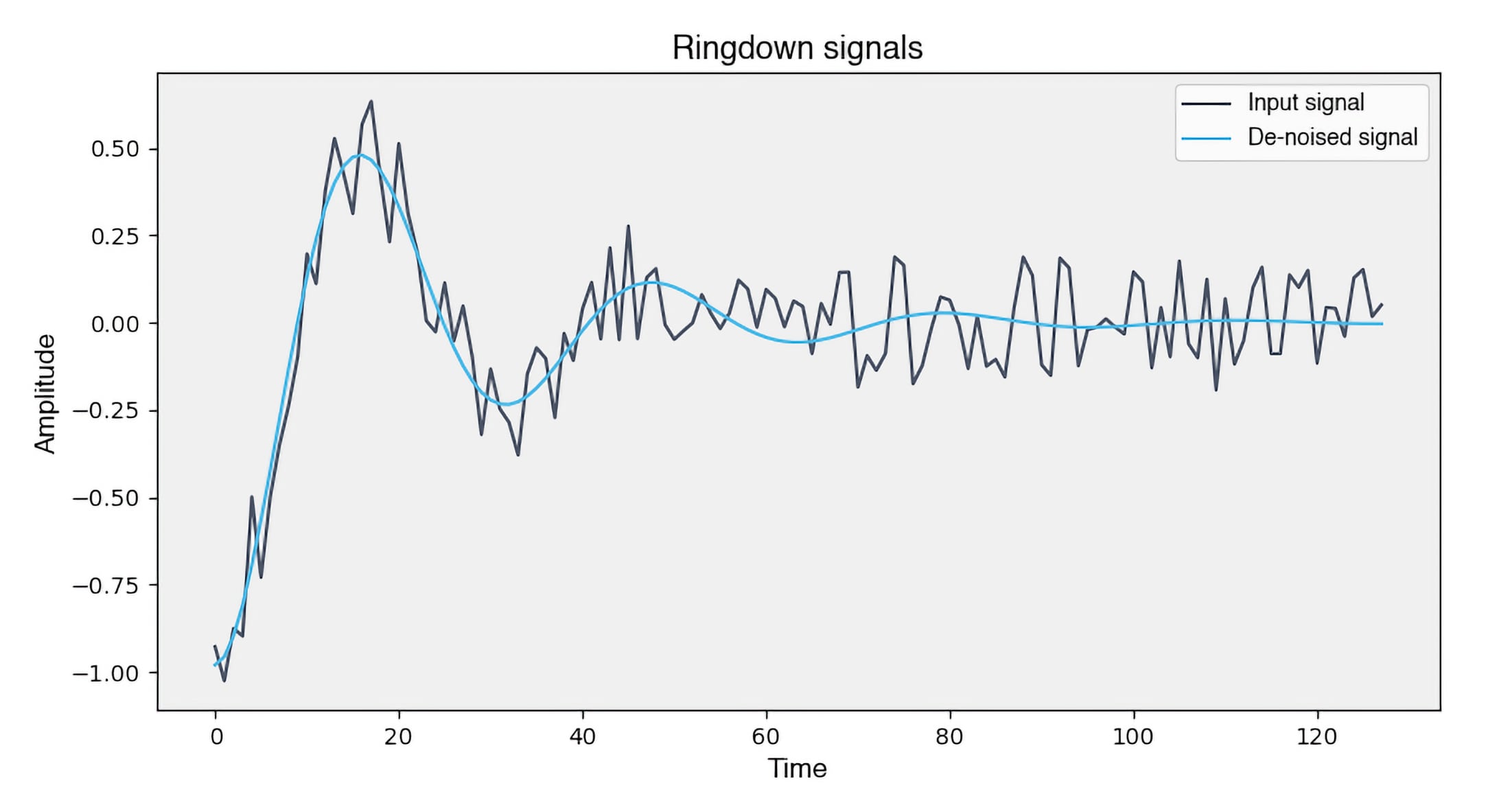
Figura 3: Un segnale ricostruito e privo di rumore dopo essere stato elaborato tramite una rete neurale.
Quali sono i vantaggi di una rete neurale basata su FPGA?
Le reti neurali vengono tipicamente costruite ed eseguite su combinazioni di CPU e/o GPU. Questo approccio offre un'enorme potenza di calcolo, ma è anche molto esigente in termini di risorse. I modelli AI di grandi dimensioni sono molto assetati di energia e spesso eccessivi per i tipi di applicazioni di elaborazione del segnale menzionate in precedenza.
Le FPGA, al confronto, non sono intrinsecamente potenti come i computer di fascia alta. Tuttavia, la loro flessibilità le rende ottimi candidati per l'implementazione di reti neurali su piccola scala. La loro capacità di elaborazione parallela è vantaggiosa per l'algebra lineare e altre complesse operazioni matematiche coinvolte nella propagazione in avanti e indietro delle informazioni attraverso la rete.
Le reti neurali basate su FPGA sono ideali per situazioni sperimentali, poiché la loro velocità nell'elaborare dati in tempo reale consente un controllo rapido e una presa di decisioni senza dover comunicare con un PC host. Le FPGA sono anche riconfigurabili, quindi l'utente può configurare rapidamente la rete neurale in base alle proprie necessità. Infine, grazie alle loro dimensioni compatte, le reti neurali implementate su FPGA possono contribuire a ridurre il consumo di risorse ed energia.
Cos'è la Moku Neural Network?
Oltre a una suite riconfigurabile di strumenti di test e misura rapidi e flessibili basati su FPGA, Moku:Pro ora offre la Moku Neural Network. Beneficiando della versatilità e della velocità di elaborazione delle FPGA, la Neural Network può essere utilizzata insieme ad altri strumenti Moku, come il Generatore di Onde, il Controllore PID e l'Oscilloscopio, in applicazioni come analisi del segnale, riduzione del rumore, condizionamento dei sensori e feedback a circuito chiuso.
Puoi utilizzare Python per sviluppare e addestrare le tue reti neurali e caricarle su Moku:Pro utilizzando la Moku Neural Network in modalità Multi-Instrumento. Questo consente di analizzare fino a quattro canali di input, o un canale di dati di serie temporali, e fino a quattro uscite per l'elaborazione dei dati sperimentali in tempo reale - tutto su Moku:Pro. La Moku Neural Network presenta fino a cinque strati densi di massimo 100 neuroni ciascuno e cinque diverse funzioni di attivazione a seconda della tua applicazione.
Se sei interessato a vedere come la Moku Neural Network basata su FPGA possa beneficiare la tua ricerca, consulta questo tutorial passo-passo. Questa guida esplora tutte le basi, compresa l'installazione di Python, la costruzione e l'addestramento della Moku Neural Network e la sua implementazione. Se sei già familiare con i concetti fondamentali di una rete neurale, puoi trovare esempi avanzati e pronti all'uso qui.

















Leave a Comment